
会社にはすでに脳がある ─ 記憶ではなく検索で作る Company Brain
以下の記事が面白かったので、簡単にまとめました。
・How we built a Single Company Brain (and how you can too)(Eric Siu)
著者の Eric Siu は、マーケティング代理店 Single Grain の CEO で、ニュースレター・ポッドキャスト「Leveling Up」を主宰する人物だ。本作は、自社で社内エージェント基盤「Single Company Brain」を作った過程を、最初の失敗と作り直しまで含めて公開した実装記である。72万インプレッション・3,000超のブックマークを集めた。先に紹介した Ashwin Gopinath の「Company Brain はフィードである」が概念とアーキテクチャの話だったのに対し、こちらは「どう作ったか・あなたはどう作れるか」という現場の手順だ。面白いのは、まったく別の立場から書かれているのに、両者が同じ結論に着地している点である。
なお、この記事自体がClaude(Opus 4.8)によって調査・執筆されたものです。
目次
- 会社にはすでに脳がある、ただし散らばっている
- 記憶を増やしたら、3週間で破綻した
- 発想の転換 ─ 記憶は原材料、検索が運用レイヤー
- 1本の通話が、6つの資産に変わる
- 5層アーキテクチャの全体像
- 第1層・第2層 ─ 捕捉と検索
- 第3層・第4層 ─ 信頼の序列と権限
- 第5層 ─ 訂正をルールに変える
- 着手の監査 ─ 6つの問い
- 所感 ─ 理論と現場が同じ場所に着いた
1. 会社にはすでに脳がある、ただし散らばっている
記事の出発点はシンプルだ。どの会社にもすでに脳はある。ただ、それが Slack や Gong、HubSpot、そして「今日たまたま休んでいる誰か」に散らばっているだけだ。
多くの人が company brain を語るときに見落とすのはここだ、と Eric は言う。価値は巨大なナレッジフォルダではない。そんなものはどの会社も持っている。本当の優位は、散らばった文脈と、チームがやるべき仕事の「あいだ」に挟まる知能レイヤーのほうにある。
・company brain が有用なのは「より多く覚えているから」ではない ・何を引き出すべきか、何を信頼すべきか、誰が見てよいか、そして訂正をどうより良い仕事に変えるかを知っているときに、はじめて役に立つ
つまり、記憶の量ではなく、記憶の使い方の設計が主題だ。
2. 記憶を増やしたら、3週間で破綻した
Single Grain も、最初は素朴な答えから始めた。社内エージェント群を作りはじめたとき、明白な解は「記憶」に見えた。全エージェントにもっと文脈を渡す。有用なメモを保存する。通話の文字起こしを残す。人間が忘れることをシステムに覚えさせる。
これは約3週間うまくいった。その後、記憶そのものがボトルネックになった。
・永続メモリのファイルがコンテキストウィンドウの約40%を食いはじめた ・エージェントは情報を多く持つようになったが、正しい情報を正しいタイミングで引けるとは限らなかった ・システムは技術的には賢くなったのに、運用的にはかえって散らかった
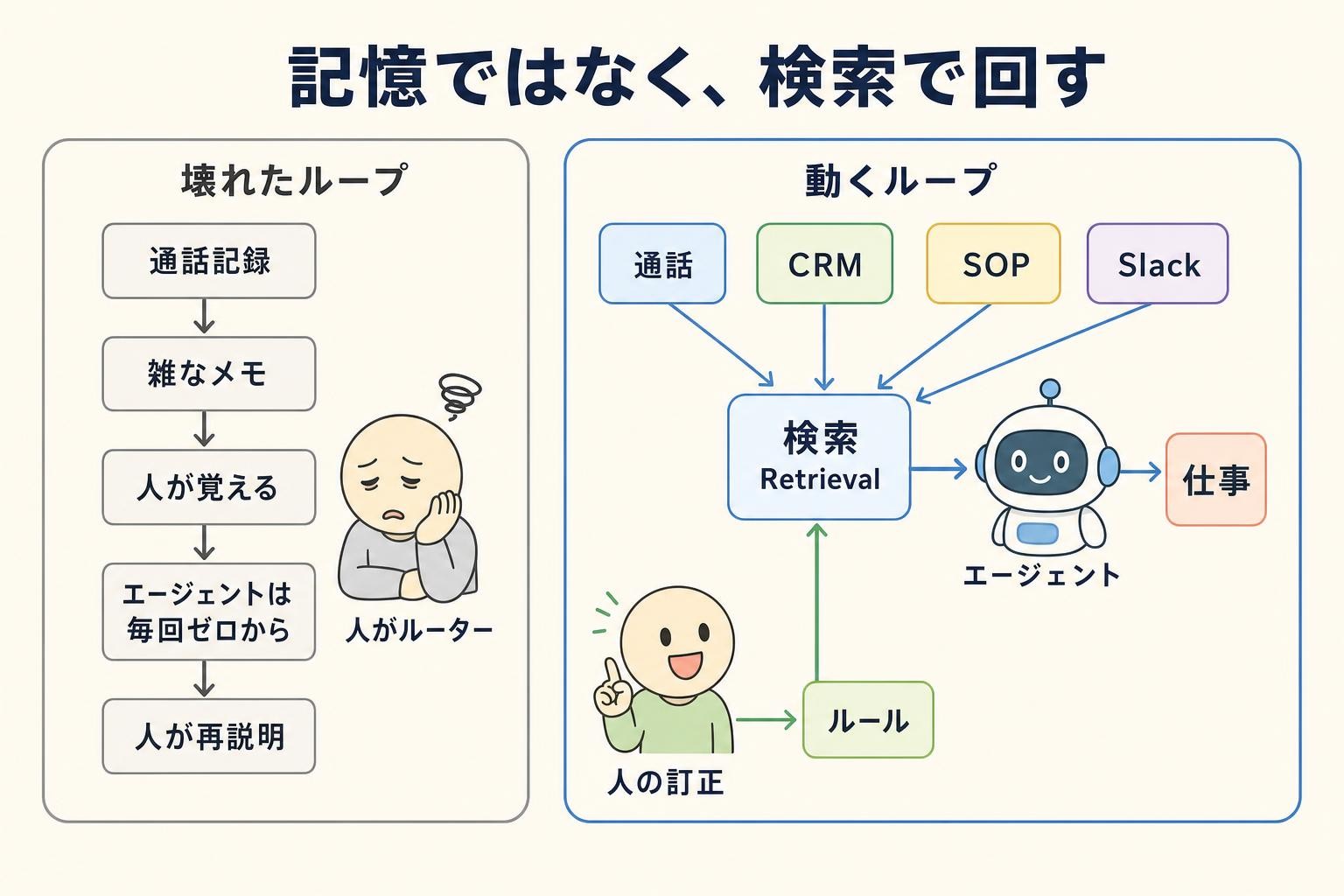
壊れた状態のループは、こうだ。通話記録ができ、雑多なメモが残り、人間がそれを覚えていて、エージェントは毎回ゼロから立ち上がり、人間が同じ説明を繰り返す。ここでは人間がルーターになってしまう。どのエージェントの出力も、誰かが正しい通話を思い出し、正しいメモをコピーし、正しい文脈を貼り、同じ間違いを5回目も訂正したかどうかに依存する。これは規模に耐えない。
3. 発想の転換 ─ 記憶は原材料、検索が運用レイヤー
そこで Single Grain はシステムを別の発想で作り直した。記憶は原材料であり、検索(リトリーバル)こそが運用のレイヤーだ、という考え方だ。
作り直した版の流れはこうなる。通話・CRM・SOP(標準作業手順)・Slack といったソースが、まず検索の層に集まる。エージェントはそこから必要な文脈だけを引き、仕事を実行する。そして人間の訂正が「ルール」に変換され、次の検索と実行に効いてくる。
一見すると小さな変更に見える。だが、これは会社全体の動き方を変える。記憶を増やすのではなく、必要な瞬間に必要な文脈を出せるようにする。脳の良し悪しは、保存量ではなく検索の精度で決まる、という宣言だ。
4. 1本の通話が、6つの資産に変わる
この設計は、すでに Single Grain の実際の業務で動いている。記事が挙げる規模はこうだ。
・永続メモリは50万トークン超 ・毎日90以上の定期ジョブ(cron)が走る ・複数の専門エージェントが動く ・数千件の営業通話がシステムに流れ込む
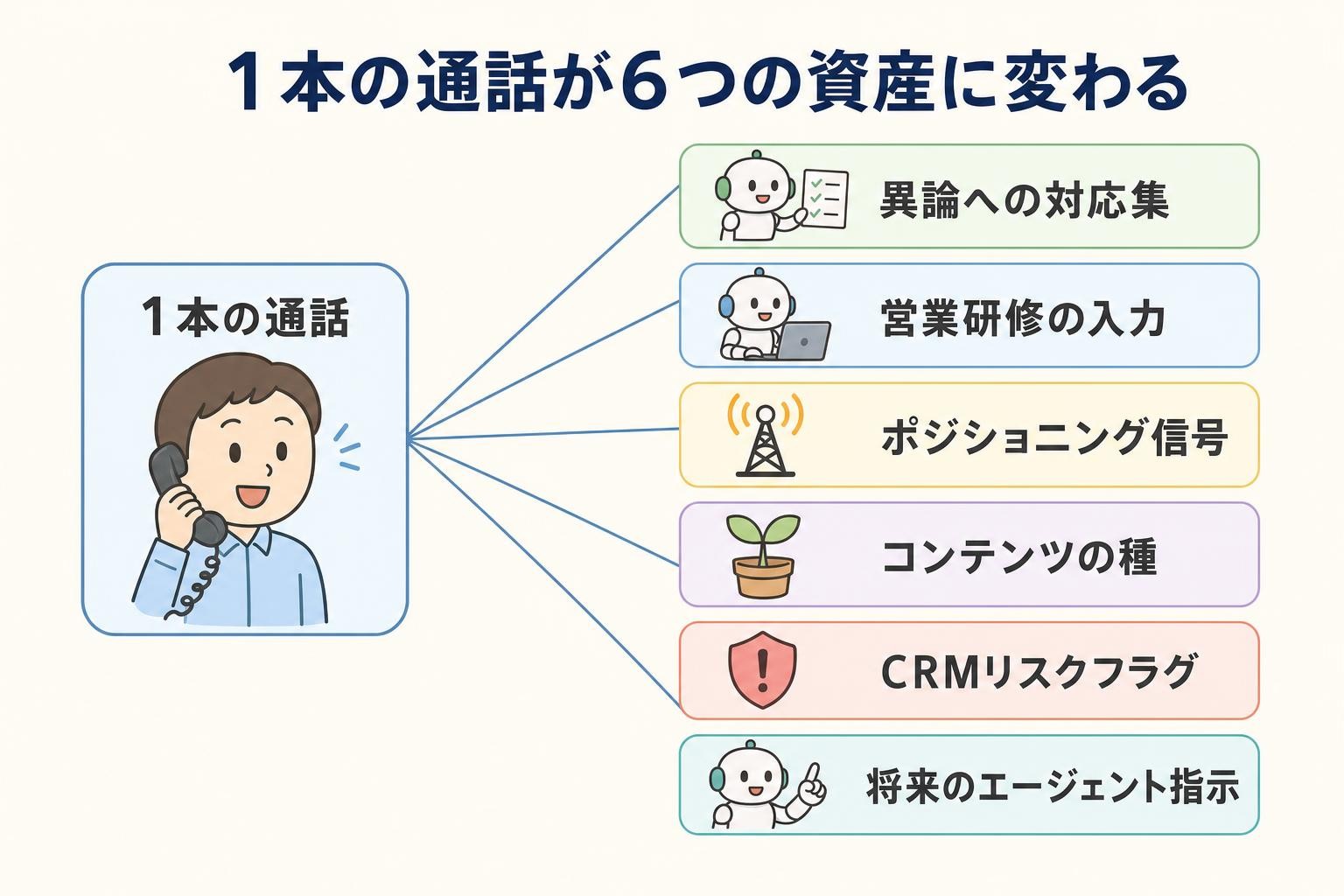
ある事例では、Gong の通話記録2,862件を運用プレイブックに変換した。別の日次取り込みの例では、15件の通話から390のインサイト、470のファクト、125のフレームワークが生成された。
数字が大きいことが重要なのではない。重要なのは、散らばった「会社の排気ガス」を、再利用できる運用知能に変換できる点だ。1本の通話は、もう単なる通話ではなくなる。異論への対応集になり、営業研修の入力になり、ポジショニングの信号になり、コンテンツの種になり、CRM 上のリスクフラグになり、将来のエージェントへの指示になる。company brain の仕事は、知識をより良い実行に変換することだ。
5. 5層アーキテクチャの全体像
記事は、このシステムを5つの層で捉える。下から積み上げると、こうなる。
・第1層 捕捉(Capture):通話・CRM・SOP などの原材料を集める ・第2層 検索(Retrieval):いま必要な文脈を正しく引く ・第3層 信頼の序列(Source Truth):何を信頼するかを決める ・第4層 権限(Permission):誰が何を使ってよいかを決める ・第5層 フィードバック(Feedback):訂正をルールに変える ・そして最上層に実行(Execution):エージェントとワークフローが仕事をする
多くの会社は第1層で始め、第1層で止まる。以降の層を作らないと、それは脳ではなく倉庫のままだ。
6. 第1層・第2層 ─ 捕捉と検索
第1層の捕捉は、チームが必ず最初に手をつけ、そして多くがそこで止まる場所だ。会議を録画し、通話を文字起こしし、Slack のスレッドを保存し、ドキュメントをベクトルデータベースに放り込む。そしてそれを「脳」と呼ぶ。だが、それは保管庫であって脳ではない。原材料は意思決定をしないし、優先順位もつけない。どの事実が古いか、どのメモが機微か、2つの文書が食い違ったときどちらを採るかも分からない。
第2層の検索は、システムが有用になりはじめる場所だ。エージェントは会社の全履歴を必要としない。目の前のタスクに効く6個ほどの文脈があればいい。
・アウトバウンドのメールを書くなら、理想顧客像・オファー・想定される異論・過去キャンペーンの成績・ブランドの声・現在の目標 ・パイプラインを見るなら、商談ステージの変化・停滞中の取引・直近の通話メモ・異論・次の打ち手・CRM の現状 ・コンテンツを書くなら、自社の本当の視点・直近の成績・承認済みの主張・すでに使った事例・その記事の根拠
多くの AI システムが静かに失敗するのはここだ。デモでは賢く見える。文脈が手で渡されているからだ。そして本番で崩れる。検索の層を誰も作っていないからだ。
7. 第3層・第4層 ─ 信頼の序列と権限
エージェントが文脈を引けるようになると、次の問題は信頼だ。どのソースが勝つのか。営業通話か、CRM のフィールドか、Slack の訂正か、古い SOP か、最新の週報か、創業者の最新のボイスメモか。これに答えないと、エージェントは整形だけがうまい、自信満々の嘘つきになる。
そこで Single Grain は、ソースの序列を運用設計の問題として扱った。あるソースは「生きた真実」、あるものは歴史的な文脈、あるものは着想の材料、あるものは社外のコンテンツに決して使ってはならないもの、あるものはパターンの参考にはなるが引用はできないもの。会社の脳が大きくなるほど、この区別が効いてくる。良い回答は、正確であると同時にソースを意識していなければならない。
第4層の権限は、全エージェントが全部を見えると危険になる、という問題に答える。マーケティングのエージェントに人事の個人情報は要らない。コンテンツのエージェントに顧客の財務は要らない。営業のエージェントに経営の内部メモは要らない。だから、ワークフロー単位の権限が必要だ。タスクが答えを生成しはじめる前に、何を使ってよいかをシステムが知っている状態にする。
これは、代理店やサービス業ではとくに重要だ。顧客の文脈、社内の文脈、見込み客の文脈、財務の文脈、戦略の文脈が、すぐ隣り合って存在する。早い段階で境界を作らないと、情報を漏らすか、システムを骨抜きにして使い物にならなくするかのどちらかになる。目指すのは「壁のない1つの大きな脳」ではなく、「ワークフローごとに正しい脳」だ。
8. 第5層 ─ 訂正をルールに変える
最後の層が、システムを複利で伸ばす。人間がエージェントを訂正するたびに、その訂正は将来の振る舞いになるべきだ。
・硬い言い回しを使ったら、声のルールを更新する ・危険な事例を引用したら、ソースのルールを更新する ・CRM のリスク信号を見逃したら、パイプラインのスキャンを更新する ・仕事を間違った先に送ったら、ワークフローのルールを更新する
ここで会社の知能が、会社の学習に変わる。フィードバックループがなければ、人はソフトウェアのお守りをしているだけだ。ループがあれば、すべての訂正が運用システム全体の訓練の1回分になる。
9. 着手の監査 ─ 6つの問い
これを自社で明日から作るなら、と Eric は監査の手順を示す。いちばん速いテストは単純だ。すでに時間を浪費している定型業務を1つ選ぶ。週次レポート、パイプラインレビュー、コンテンツ作成、営業の追客、顧客のオンボーディング、提案書作成のどれでもいい。そして6つを問う。
- この業務はどのソースに依存しているか
- ソースが食い違ったとき、真実はどれか
- エージェントが毎回必要とする文脈は何か
- エージェントが決して見てはいけない文脈は何か
- 繰り返し起きる人間の訂正は何か
- 1つの訂正を、どうやって将来のルールにするか
これに答えられないなら、その業務を自動化する準備はまだできていない。やれば、混乱を速くするだけだ。
レポートで実際にそうだった、という。古い流れは、データを引き、手で解釈し、経営が追加で質問し、さらに補足を求める、というものだった。週次レポートのループは、データ収集に約25分、そこにフォローアップで数時間がかかっていた。脳が正しい文脈を持つようになると、答えは60秒以内に返るようになった。
時間の節約も嬉しい。だが、より大きな勝ちは意思決定のレイテンシだ。会社がより良い問いをより速く立てられると、動き方そのものが変わる。リーダーは誰かがダッシュボードを組み上げるのを待たない。現場はゼロから始めない。エージェントは毎朝バカになって目を覚まさない。
10. 所感 ─ 理論と現場が同じ場所に着いた
この記事が面白いのは、結論が、私が先に紹介した Ashwin Gopinath の Company Brain 論とほぼ完全に重なっていることだ。Ashwin は記憶設計の理論家として「知識は待つが、記憶は参加する」「データ・ナレッジベース・メモリは別物だ」と書いた。Eric Siu はマーケティング代理店の経営者として、まったく違う語彙で「記憶は原材料、検索が運用レイヤー」と書いている。出発点も職業も違うのに、同じ場所に着いた。
とくに象徴的なのが、永続メモリがコンテキストウィンドウの40%を食ってシステムが詰まった、という失敗談だ。これは Ashwin が「大きなコンテキストは記憶ではない」「12万トークンの再発見税」と呼んだ現象と、同じものを別の角度から見ている。記憶を足し続ける設計は、ある規模で必ず行き詰まる。両者がそろって、足すのではなく「何を引き、何を信じ、何を忘れるか」を設計せよ、と言っている。
理論の側(Ashwin)が「Company Brain とは何か」を定義したのに対し、現場の側(Eric Siu)は「5層と6つの問い」という、手で作れる型を渡してくれる。捕捉し、正しい文脈を引き、何を信じるかを決め、使ってはいけないものを守り、すべての訂正をルールに変える。脳が複利で伸びるのはそこだ。
最後の一文が刺さる。AI で勝つのは、最大のプロンプトライブラリを持つ会社ではない。最もクリーンな知能レイヤーを持つ会社だ。
参照: How we built a Single Company Brain (and how you can too) by Eric Siu